
Cerebras Systems: A Deep Dive
With a strong wind in its sails, Cerebras finally brings its giant chip to the world... and to the stock market


Friends of NFTBC.
As seasoned NFTBC readers will know, I am particularly drawn to stories of unconventional business success. Naturally, these sorts of stories are rarely obvious in the beginning - so any satisfaction in the pursuit comes from following them over time and living inside the story while it writes itself. All the better, if I can make some useful investment returns along the way. Cerebras Systems is an example where I have been following the story for about five years and an investor for just over two years. With Cerebras having recently filed an S-1 and an IPO looking imminent, now seems like the right time for a post. But I have been of two minds as to whether I should write one. AI, IPOs, hype - these are certainly not the traditional NFTBC territory you’re used to, and to some extent they did put me off from wanting to involve myself. But on the other hand Cerebras is, in my view, an extraordinary business - and a fascinating one. It’s worth writing about. I’m also well aware I’m posting this at a time of especially high enthusiasm for semiconductor stocks - and this unsettles me to some degree. But equally, if ever there was a propitious moment for Cerebras to raise needed capital on the stock mark, this is it.
This post is intended for curious readers with an interest in unconventional businesses doing interesting things. It’s probably less relevant for those who want to go deep into the weeds on engineering questions. But all are welcome. Additionally, the post will be much more concerned with the business itself rather than IPO dynamics.
Let’s begin.
[NFTBC does not give investment advice. Please do your own research.]
Introduction
Since its founding a decade ago, Cerebras has been in the business of inventing, producing and selling a highly unconventional computer system with specific design intent for AI applications. What makes Cerebras’ system so unusual is the way they’ve gone about it - using an entire monolithic 300mm silicon wafer as the basis of their processor, rather than dicing their wafers up into small chips like everyone else does. Doing it this way also necessitates rethinking the entire system as well as the manufacturing process and supply chain: from packaging to power to cooling to software. And there are good reasons why no one else does this - for decades it was supposed to be a dead end. Cerebras’ founders decided to do it anyway, succeeding against all the odds - they’ve now built something unique and very hard to replicate. As to why you might even want a ‘wafer-scale’ processor, I’ll cover some of that later. But suffice to say for now that the founders came to realise in late 2015 that the future computational requirements of AI, would look very different to those that the existing architectures were designed for (e.g. the graphics processing unit). And so, the Cerebras Wafer-Scale Engine (WSE) is what you get when one of the most determined, experienced and innovative systems design teams comes together at the right time, with the right backers, a bit of luck - and with a blank sheet of paper.
Cerebras’ current system, the CS-3, was released two years ago. The CS-3 was primarily intended for model training and provided an elegant solution for simple near-linear scaling out to large clusters. I thought this was the way things were going to go. But despite impressive demonstrated performance the CS-3 has remained very niche in training - training being where Nvidia’s moat is strongest. Within months of the CS-3 launch, in mid-2024 Cerebras quickly pivoted to inference in order to capitalise on the emerging shift to inference-time compute - or smarter ‘thinking’ models. In 2026, we’re all familiar with thinking models - they’ve become mainstream. And we’re all familiar with waiting while the model thinks. To calibrate your expectations here, the CS-3 typically runs models around 10-20 times faster than GPUs - in practical terms this means that chat responses come back more or less instantly without having to wait. Seeing is believing of course, so you can try out Cerebras Chat for free at this link. Or you can just watch Cerebras code an interactive pool game in 12 seconds:

Of all places, I came to be aware of Cerebras some years ago via GSK - yes, the stodgy old big pharma! (see my GSK post here). One of the lesser-known things about GSK is that they have perhaps the leading in-house AI and machine learning capabilities in the pharma industry. They were also Cerebras’ first commercial customer. Intriguingly, it was actually GSK who sought out and approached Cerebras - a complete unknown at the time and only recently out of stealth mode. The GSK AI/ML group had some big problems they were struggling to solve with GPUs. They looked into rightsizing the hardware to their problem, rather than the other way round - Cerebras had the hardware for the job. The two companies remain partners years later.
It took Cerebras around four years to design and launch their first system - a process defined by formidable challenges that they ultimately overcame. It took another six years to get traction with hyperscale customers. But they stuck at it, kept making their case and made a couple of important pivots. And so, after years of having to promote an offbeat roster of reference customers such as GSK, TotalEnergies, Mayo Clinic and G42, Cerebras can finally point to major megawatt-scale contracts with OpenAI and AWS. The foot is now firmly in the door. It’s no coincidence that the list of chip startups with major cloud deployments is particularly short. The barriers to entry are mighty. Turning up with something just a bit better simply will not do - you have to turn up with something an order of magnitude better, and that was the plan from the start. In many respects the WSE was ahead of its time but it’s now coming into its own.
In my case, it took a good couple of years for the potential of wafer-scale computing to dawn on me. By early 2024, I had become convinced enough to buy Cerebras shares in the private market. Any early excitement around Cerebras had now been squeezed out by Nvidia’s tightening grip on the AI narrative. Private market appetite for wafer-scale was minimal - which, of course, is exactly what made it interesting.
In the domain of frontier models and the underlying infrastructure that makes it all possible, we are, of course, talking about a space that is moving with extraordinary velocity. The number of people (or more accurately, teams of people) who are able to synthesise all of the associated technologies at the leading edge and hold a useful idea of where things might be heading, is incredibly limited - and almost all such people are active participants in shaping this future rather than investors passively trying to make sense of things from the sidelines. So we should be honest with ourselves: practically all of us are mere passengers. As I have said a few times before, investing for me is sometimes about striking the right balance between knowing too much and too little. It seems to be the case that some of Cerebras’ first venture backers felt the same way1 - they knew enough to grasp the significance of what the founders were proposing, but perhaps not enough to be scared off from trying. But most importantly, the reason Cerebras got funding at all was because the VCs were backing a team - in this case, a team who had worked together for years and had founded a successful systems venture previously (SeaMicro). They’ve done it twice now, and achieved something even more challenging the second time around. So in its most simplified form, the Cerebras thesis might be stated something like this: whoever had the requisite foresight, ingenuity, experience and persistence, against all the odds, to first create the Wafer-Scale Engine and then drive its adoption into the mainstream - it’s worth betting on those people and whatever they’re going to do next in the field of AI computing.
The AI market is moving extraordinarily quickly, and we are well-positioned to anticipate its twists and turns
- Cerebras Founders Letter
It’s worth stating at the outset that the range of outcomes for Cerebras is particularly wide and, in the context of an IPO and a possible AI infrastructure bubble, this will result in highly polarised views and speculation every which way. Cerebras produced around $500m in revenue for 2025, and per the S-1/A the IPO market cap looks like it could be in the region of $26 to $27bn. As the sceptics will rightly point out, these sorts of starting valuations rarely produce attractive prospective returns. Sceptics might also point to extreme customer concentration, not to mention the constant uncertainty of when the AI capex bubble will eventually pop. But on the other hand, if Cerebras executes to the full extent of the contracts disclosed in its prospectus, it could conceivably ramp to well over $10bn in revenue over the next five years - for context, this might just sneak Cerebras into the top 10 fastest ever growing businesses from product launch (roughly similar to Facebook’s 2004-2014 run). And, let’s say, if Cerebras can make it to just 5% of Nvidia’s current revenue run-rate by the early 2030s (that’s ~$15bn), you could still be looking at a $100bn market cap business even with an extreme de-rating from 50x revenue to 7x. And I want to be clear about this: Cerebras is not an “Nvidia killer” such as you see in some of the sensationalist headlines - the thesis is more about winning a small slice of a very large pie. We’ll look at scenarios later on. For my part, I think Cerebras has a genuine shot at getting big quite quickly. But it’s by no means a dead cert and there are important risks and considerations that we’ll look at.
I have deliberately decided to try to make this post as non-technical as possible - although it does assume some base level knowledge around certain terms and concepts. I’m going to link to some of Cerebras’ technical materials/presentations and I suggest diving in for those who want to go there. From following Cerebras over time, I have encountered a good deal of punditry, typically concerning why the company will remain limited to only a highly specialised niche or why its systems will surely prove economically unviable. Some of this commentary is simply a result of insufficient familiarity with the company, and some of it seems to assume that Cerebras will not continue to adapt or make advances in future system generations. But some observations are fair and worth making note of - which we’ll touch on later. I’ll try to avoid making too many technology-related claims of my own, especially where they might be contentious - to do otherwise, I risk getting in over my head. So I’ll try to stick to claims that seem fairly robust and highlight where I’m choosing to put my faith in others. It’s inevitable I’ll get some things wrong, so I shall endeavour to clear up mistakes later on.
But if there’s only one thing you need to understand about the Cerebras thesis it’s this: speed. It’s generally uncontentious to say that the principal bottleneck in inference output speed is having to constantly move massive amounts of data from memory to compute - move the data too slowly and the processor sits idling while waiting to be fed. Cerebras’ answer is to pack an entire wafer with the very fastest type of memory (SRAM) interspersed among the compute - data travels only tiny distances and through incredibly fat pipes. If you have to move data between individual chips (like everyone else does), the distances get longer and the pipes much thinner. This is why there’s nothing else remotely as fast as the CS-3 at inference:
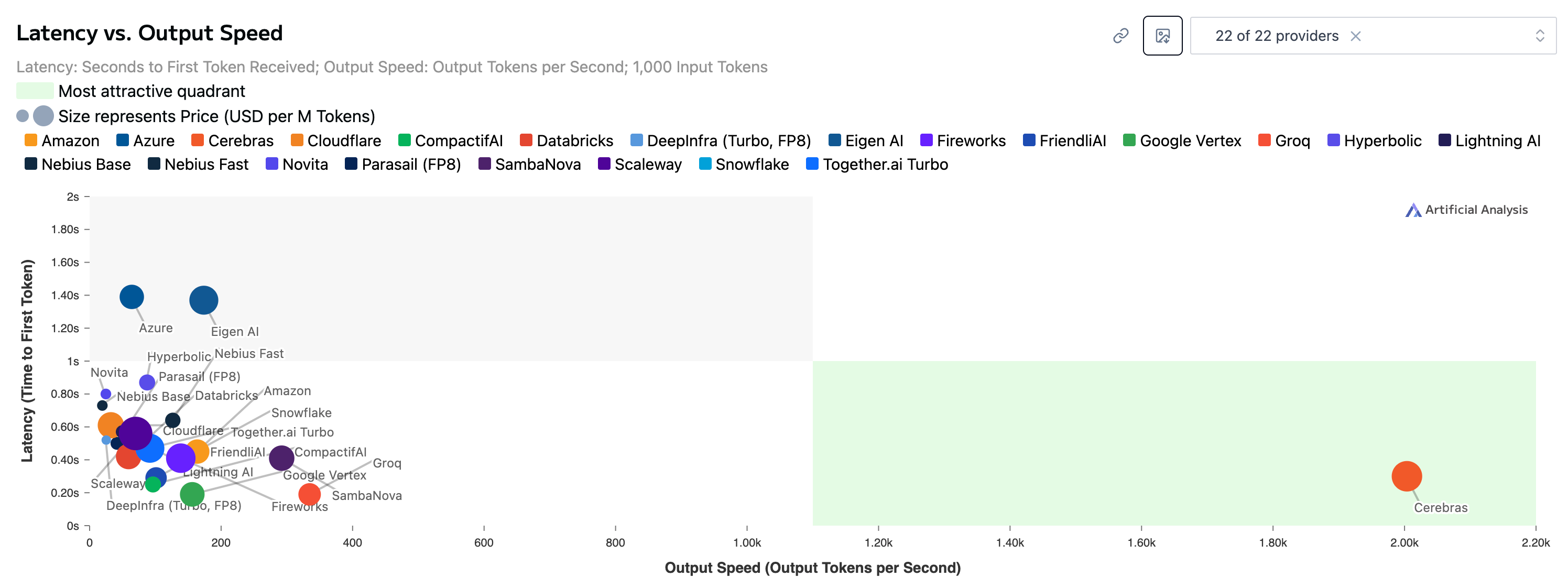
Moreover, it has become clear that much higher output speed is able to command a price premium. In a similar vein, Anthropic have shown they can charge 6x more for their ‘fast mode’ at 2.5x the speed.
Cerebras is the only player who can produce a wafer-scale system such is required for extreme memory bandwidth. Extreme memory bandwidth enables extreme speed. Extreme speed potentially enables a breakout from the commodity token space through premium pricing and new use cases. Competitors are, of course, lining up to enter this gigantic market. And it’s also true that barriers to entry in chip design may have come down in some respects - there’s far more venture money washing around in semiconductors compared to a decade ago and the hyperscalers have deep pockets and motivation. Thus far, there’s not much evidence of anyone else going wafer-scale and, moreover, Cerebras owns important IP in that domain, having pioneered it. And, as we shall learn, it’s by no means easy. I therefore believe that barriers to entry in wafer-scale remain intact. Most alternative approaches to wafer-scale appear to retain the ‘thin pipe’ problem, go after cost rather than speed or else sacrifice vital programmability (which has obvious limitations if the models keep changing). And perhaps most importantly it’s important to weigh up the following considerations: 1) the CS-3 wasn’t even designed principally with inference in mind and 2) no frontier lab has yet designed a model specifically to take advantage of wafer-scale benefits and to optimise around the constraints. Both of these things are about to change. It’s clear that Cerebras and its partners have big ambitions for major system improvements from here - more on that later.
But who knows? Maybe the wafer-scale critics will have the last laugh in the end. Maybe the economics won’t play out competitively or maybe Cerebras will struggle to keep up with Nvidia’s relentless pace. Maybe they’ll struggle to manufacture these systems in the necessary volumes. Or perhaps they (or their largest customer) will run out of cash. We’ll review some of the risks later on. But what excites me most is that I don’t think we’ve even seen Cerebras’ A game yet. Here’s Cerebras co-founder and Chief Architect, Michael James, speaking at the end of last year:
If you look at the next designs that we’ll come out with, they might make [the WSE-3] seem quaint.
This? Quaint?:

I’m curious to see what comes next.
The Meaning of Speed
I was reading about George Stephenson, the great steam train pioneer, earlier this year. In Great Britain the idea of travelling twice as fast as the fastest horse-drawn mail coach was once considered absurd, unfeasible and dangerous, not to mention unnecessary - a dead end. And the country had previously invested heavily in a comprehensive network of canals for the efficient horse-drawn conveyance of commercial goods - the canal network was itself a paradigm shift and a key accelerant of the industrial revolution in Britain. So when in the 1820s Stephenson proposed the world’s first intercity steam locomotive railway between Liverpool and Manchester, he faced a good deal of scepticism:
George Stephenson’s idea was at that time regarded as but the dream of a chimerical projector. It stood before the public friendless, struggling hard to gain a footing, scarcely daring to lift itself into notice for fear of ridicule. The civil engineers generally rejected the notion of a Locomotive Railway; and when no leading man of the day could be found to stand forward in support of the Killingworth mechanic, its chances of success must indeed have been pronounced but small. But, like all great truths, the time was surely to come when it was to prevail.2
I am, of course, just having a bit of fun here. But I do enjoy these stories where some maverick succeeds with an audacious groundbreaking idea against the odds - and the analogy of moving from the canal age (i.e. GPU) to the steam locomotive age (i.e. Wafer-Scale Engine) is a tempting one. Stephenson got his railway in the end and it changed the meaning of speed for the whole world:
Notions which we have received from our ancestors, and verified by our own experience, are overthrown in a day, and a new standard erected, by which to form our ideas for the future. Speed – despatch – distance – are still relative terms, but their meaning has been totally changed within a few months: what was quick is now slow; what was distant is now near; and this change in our ideas will not be limited to the environs of Liverpool and Manchester – it will pervade society at large.3
The rest is history, as they say. Back in Stephenson’s day, there were those who pointed to the efficiency of the existing canal system to demonstrate why railways were unnecessary. They weren’t wrong. But it showed a lack of imagination. Even today’s canal baron, Jensen Huang, is finally hedging his bets and ponying up for some steam engines of his own - as evidenced by Nvidia’s recent acquisition of Groq (the closest Cerebras has to a fast inference peer). The first sections of intercity track are now being laid.
Staying on the topic of speed, Cerebras co-founder and CEO Andrew Feldman likes to draw the more modern analogy between dial-up/broadband internet and slow/fast inference. I’m old enough to have had my formative internet experiences with dial-up modems. And Feldman has a point - waiting for a model to respond in 2026 conjures up old memories of loading webpages 30 years ago. For any patient youngsters or nostalgic oldies, you can see what this was like here:
What did it mean when broadband arrived and we no longer had to wait? The internet changed: websites could become far more data rich, streaming, cloud computing, you name it - entirely new business models emerged and their effects continue to ripple through our world today. And as the world moves forward, expectations change - Feldman and others like to point to research carried out by Google and Amazon some years ago showing how mere milliseconds of latency can cause a reduction in traffic or even revenue.4
So what of fast inference? Here’s how Cerebras co-founder Sean Lie put it when they announced an experimental ultra-fast coding tool with OpenAI a couple of months ago (Codex-Spark):
What excites us most about GPT-5.3-Codex-Spark is partnering with OpenAI and the developer community to discover what fast inference makes possible—new interaction patterns, new use cases, and a fundamentally different model experience. This preview is just the beginning.
-Sean Lie, CTO and Co-Founder of Cerebras
Readers may have their own views on this, but in the prospectus (p121) Cerebras cites coding as a strong example, as well as real-time insights in deep research and voice applications. We’ll just have to see what emerges in the months and years ahead. But the trend is clear: more thinking time » more inference » more waiting (unless we do something about it):
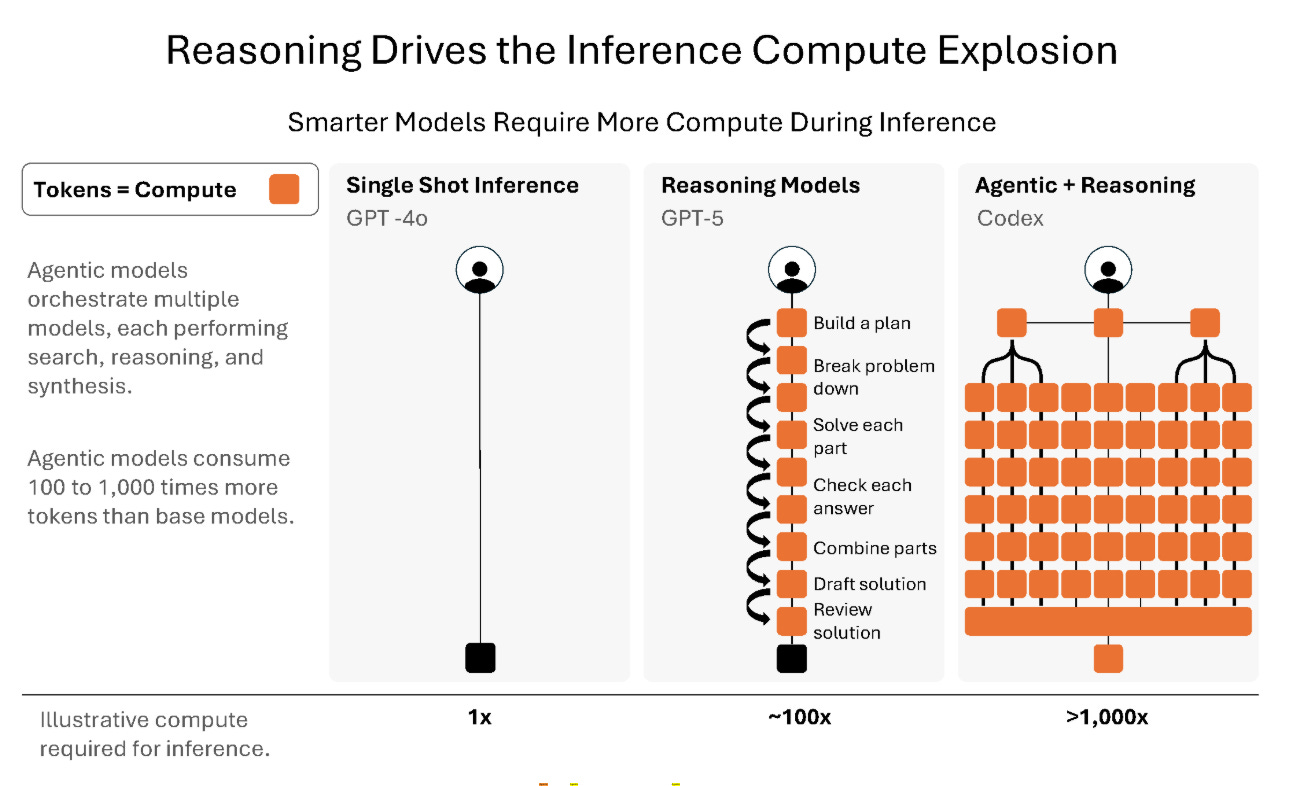
Here ends the complementary section of this post - thank you for reading! In the remainder, we will cover the following topics:
The Road to Wafer-Scale
Brief Thoughts & Speculations on Tokenomics
The Roadmap: what we know + some possibilities
Business Model & Sizing The Opportunity
Risks & Other Considerations
Final Thoughts: Moat
The Road to Wafer-Scale
The Cerebras origin story gets underway around 20 years ago.
SeaMicro
At the time, Gary Lauterbach was a highly experienced architect at Sun Microsystems. He had designed Sun’s latest generations of powerful server chips. Andrew Feldman was a former network equipment executive turned entrepreneur-in-residence at a VC firm. Both had, via different paths, arrived at the same conclusion: a new kind of efficient server hardware was needed to address the massively escalating challenge of datacenter power consumption. Feldman decided to start a company, but he needed a technical founder to join him. He had the right network and VC connections, while Lauterbach had the engineering expertise. A former colleague of Feldman (who
